GettingStarted
Duke can be used to find duplicate records inside a single table/data source, or it can be used to find records in different tables/sources which most likely represent the same real-world entity.
To run Duke you need an XML configuration file. You also need to put duke-**.jar and lucene-**.jar on the classpath.
To run Duke, give the command
java no.priv.garshol.duke.Duke
That will print out the available options. For help on how to set things up optimally, see the TuningGuide.
There is an API for embedding Duke into web services and applications, and support for incremental processing.
First, Duke loads data from the specified data sources. Then, the data is cleaned (that is, normalized), by calling a Cleaner (an instance of the Cleaner interface). The column elements inside the data sources pick up data from the source which are cleaned (if a cleaner is specified) and put into a record in the specified property.
Records are compared according to the configuration on the property elements. Comparison is done by a Comparator (an instance of the Comparator interface). For more detail on this process, see HowItWorks.
There are two modes of operation: DeduplicationMode and RecordLinkageMode.
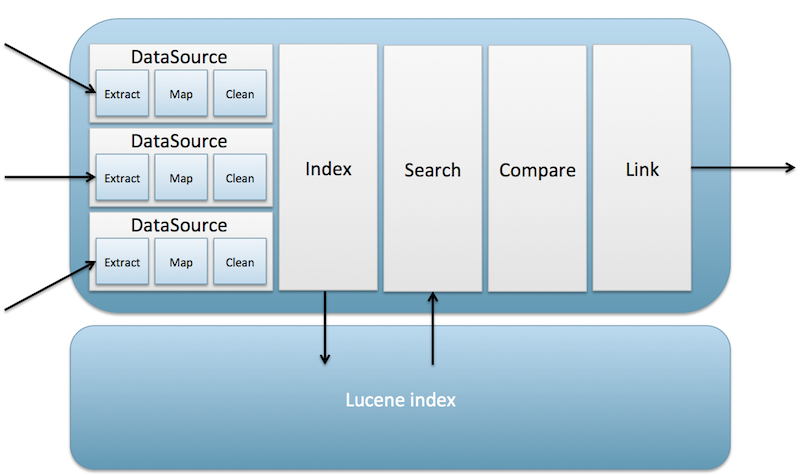
Duke will report its findings to the MatchListener. You can write your own MatchListeners, or use those which come with Duke.