Data Acquisition
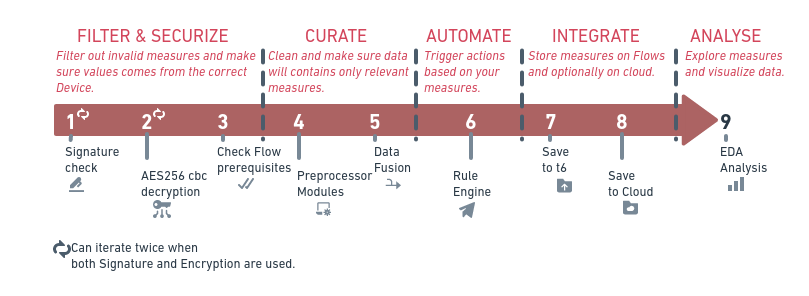
t6 Data Integration is a process done in 8 distinct phases - and the nineth phase refers to the data analysis itself.
Each Flow can contain the preprocessor attribute (optional) as an array of preprocessor(s).
Or, by adding a Datapoints, the payload can have this preprocessor attribute as well.
Payload preprocessor is overwritting the Flow when both are having the attribute.
During phase 4, preprocessor can do several modifications and controls on measures: transformation, convertion, sanitization, validation and Automatic identification and data capture (AIDC).
Incoming values posted to Flows can be modified by 1 or multiple preprocessor(s). So before it comes to the Rule engine and before any storage on TimeseriesDb. The available transformers are the following:
| Mode | Example input | Example output |
|---|---|---|
| camelCase | Consequatur quis veniam natus ut qui. | consequaturQuisVeniamNatusUtQui |
| capitalCase | Consequatur quis veniam natus ut qui. | Consequatur Quis Veniam Natus Ut Qui |
| constantCase | Consequatur quis veniam natus ut qui. | CONSEQUATUR_QUIS_VENIAM_NATUS_UT_QUI |
| dotCase | Consequatur quis veniam natus ut qui. | consequatur.quis.veniam.natus.ut.qui |
| headerCase | Consequatur quis veniam natus ut qui. | Consequatur-Quis-Veniam-Natus-Ut-Qui |
| noCase | Consequatur quis veniam natus ut qui. | consequatur quis veniam natus ut qui |
| paramCase | Consequatur quis veniam natus ut qui. | consequatur-quis-veniam-natus-ut-qui |
| pascalCase | Consequatur quis veniam natus ut qui. | ConsequaturQuisVeniamNatusUtQui |
| pathCase | Consequatur quis veniam natus ut qui. | consequatur/quis/veniam/natus/ut/qui |
| sentenceCase | Consequatur quis veniam natus ut qui. | Consequatur quis veniam natus ut qui |
| snakeCase | Consequatur quis veniam natus ut qui. | consequatur_quis_veniam_natus_ut_qui |
| upperCase | Consequatur quis veniam natus ut qui. | CONSEQUATUR QUIS VENIAM NATUS UT QUI. |
| aes-256-cbc | Consequatur quis veniam natus ut qui. | e.g.: f5596c8aa3bfaf03882554760518e4b7:f30aaa6f54e175d2a4579eb228[... ...]9469810ba0a495d1643. The string before : refers to vector iv |
In the case of mode="aes-256-cbc", the payload must contains an extra attribute: object_id with the value of the Object which knows the secret.
E.g:
"preprocessor": [
{
"name": "transform",
"mode": "snakeCase"
}
]The convert preprocessor is a very simple unit converter for the main following units:
- time
- distance
- mass
- volume
- storage
- things
- temperature 💥
E.g:
"preprocessor": [
{
"name": "convert",
"type": "distance",
"from": "km",
"to": "m"
}
]The sanitize preprocessor is aiming to make sure the value is using the expected Datatype.
Note: This sanitization is forced from t6 according to the Flow, but it can also be added manually if you'd manually need to sanitize prior any other processor.
E.g:
"preprocessor": [
{
"name": "sanitize",
"datatype": "float"
}
]An additional attribute can be added when Adding a Datapoint to t6 and containing the uuiv-v4 of the corresponding Datatype. In this case the (automatically added) Sanitization will use the specified Datatype.
E.g:
"data_type": "e7dbdc23-5fa8-4083-b3ec-bb99c08a2a35",Validation on preprocessor aims to validate the value sent to t6 and/or reject from any storage in case the value does not pass validation test. Validation allows Decision Rule to follow up on the value.
The validation are the following :
| Test | Example input | Result |
|---|---|---|
| isEmail | rejectedEmail@______domain.com | ❌ due to invalid domain name |
| isEmail | AcCePtEdEmail@domain.com | ✅ |
| isAscii | Rejected char 😀 | ❌ due to invalid character |
| isBase32 | aBCDE23= | ❌ |
| isBase32 | 89gq6t9k68== | ✅ |
| isBase58 | aBCDE23= | ❌ |
| isBase58 | a4E9kYnK== | ✅ |
| isBase64 | aBCDE23== | ❌ |
| isBase64 | QmFzZTY0== | ✅ |
| isBIC | ABC-FR23GHI | ❌ |
| isBIC | ABCFRPP | ✅ |
| isBoolean | Truezz | ❌ |
| isBoolean | True | ✅ |
E.g:
"preprocessor": [
{
"name": "validate",
"test": "isEmail"
}
]AIDC preprocessor expect to deals with images preprocessing to identify objects, faces and facial expressions.
AIDC modes are the following :
| Mode | Purpose |
|---|---|
| faceExpressionRecognition | Identify the best match expression (neutral, happy, sad, angry, fearful, disgusted, surprised) from the 1st face detected in the image |
| genderRecognition | Identify the gender (male, female) from the 1st face detected in the image |
| ageRecognition | Identify the age from the 1st face detected in the image |
E.g:
"preprocessor": [
{
"name": "aidc",
"mode": "faceExpressionRecognition",
}
]Sensor Fusion is the process of merging multiple values together. Data Fusion on t6 allows to combine multiple measures from several Flows (Tracks) onto another Flow (Primary). This "Fusion" will be made according to an algorithm defined directly on the Primary Flow. Data Fusion is working after the preprocessor engine is transforming the value. And after the Fusion, the value can optionaly be saved to the Primary Flow before it goes to the Decision Rule engine.
Data Fusion preprocessor is at an early stage (means beta version). Please contact us for more details.
The current Data Fusion implementation is working on the following: a timed buffer is storing the measurements values from each tracks until TTL it expired. And TTL is customizable for each Flows/Tracks distinctively. When a Datapoints is sent to t6, the Data Fusion compute the fusion from all values in buffer. Smaller the Buffer is, accurate the time-based-fusion will be. :-) A TTL of 60 (seconds) should be good enough ; but it may vary according to your measurements needs.
Note : A Fusion is processed only when at least one measurement is available (and not expired) in Buffer.
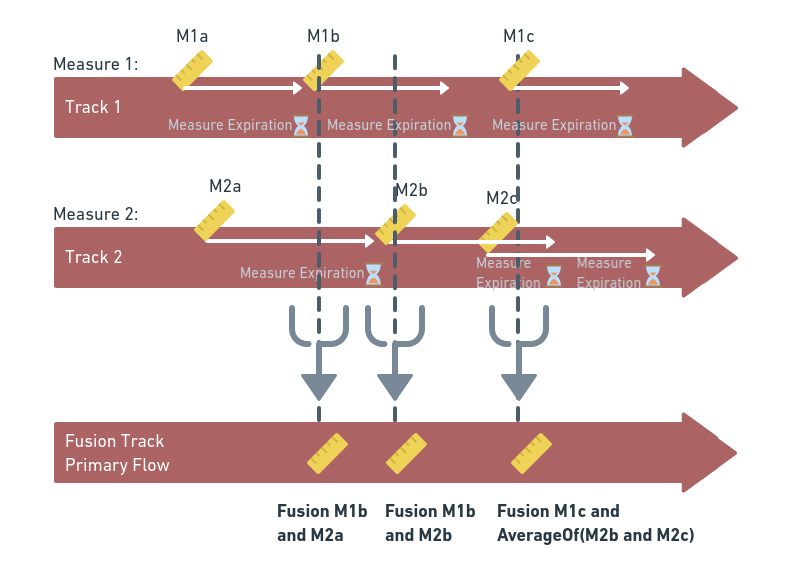
Data Fusion require few settings on your ressources :
- First, each Flow needs to set their "track_id" attribute refering to their Primary Flow.
- Then, each Flow needs to set their own Time To Live (TTL) that will be used in the preprocessor and Fusion-Buffer before expiration - default buffer duration: 1 hour.
- Finaly, by adding Datapoints, Buffer is populated.
- Once all Tracks have one or more value in Buffer, preprocessor will automatically compute Data-Fusion.
Note : When the Track is having multiple Datapoints on Buffer, a simple average is calculated prior to the Fusion.
When fusion is processed during the add Datapoints Api call, the following extra node is outputed to json payload:
E.g:
"fusion": {
"algorithm": "average",
"messages": [
"Fusion is elligible.",
"Fusion processed."
],
"measurements": [
{
"id": "aea1a21a-97f0-467d-b062-180ae7154b86",
"count": 4
},
{
"id": "c25d3f9f-37eb-4d9a-a168-259af480b111",
"count": 6
}
],
"initialValue": 939.346,
"primary_flow": "ea8a2d07-3318-4eb0-a63c-7a66aa10a1c9",
"correction": 203.7756875
}In this example, we can see the algorithm being used in the Data Fusion as well as an Array of messages (to debug and clarify).
Then, the initial Value is the injected value coming from the preprocessor before it enter the Fusion (so this value does incude the sanitization ; and the primary_flow correspond to the Flow where data are saved (provided the generic attribute save = true).
The node measurements contains a list of Tracks with their relative number of available values. The latest attributes correction is the difference between the initialValue and the Fused value.
Note : The attribute value from the output payload after a Fusion is modified according to the computed Fusion value.
Note : The attribute time from the output payload after a Fusion is modified according to the computed Fusion time (a date exatcly in the middle of the buffer range).
Sending Datapoint with the attribute fusion is allowing to set the algorithm to be used in the Fusion.
E.g:
"fusion": {
"algorithm": "weighted_average"
}The available algorithms list is the following:
| Algorithms Name | Expected Data-Type | |
|---|---|---|
| average | Float | This will use a uniform 1 weight on each measure |
| average_weighted | Float | This will use a custom weight from the Flow |
| mht | ||
| mmse | ||
| nn | ||
| nearest_neighbors | ||
| pda | ||
| jpda |
Described into Dedicated Decision-Rule section
There are 2 options to store measures on t6:
- on t6 server directly;
- on InfluxData Cloud;
Analysing measurzes is not actually part of Preprocessor. It is described into Dedicated EDA section